
Multi core -> Multiprocessor
Thread 개념을 이용해 parallel programming을 해야 한다. (Multithreading)
Cache Coherence
: Multicore 환경에서 각 CPU Core에는 개별적인 Cache가 존재하고, 이 Core들은 공통된 Bus를 통해 Memory에 접근하는데, 이때 각 Core Cache, 그리고 Main Memory 사이에서 Data들의 Consistency를 어떻게 유지할 것인가?
Bus snooping
https://gusdkstudyhard.tistory.com/139
[OS] Multiprocessor Scheduling(1) - Cache Coherence(캐시 일관성) & Bus snooping(버스 스누핑)
Single Core 환경은 (CPU - Cache) ----- Memory 형태로 되어 있다. Cache는 Main Memory보다 용량은 작지만, 주요 data들을 모아 둔 작고 빠른 임시저장장치이다. 이 Cache를 이요함으로써 CPU와 Memory 간의 다소 느
gusdkstudyhard.tistory.com
1편에 적었다.
Synchronization
core가 n개라면 최대 n개의 core가 각각 Queue에 접근하여 enqueue하거나 dequeue하는 상황이 생길 것이다.
Application program이 Shared Data를 접근할 경우에는 lock과 unlock으로 synchronization을 보장해 주어야만 의도치 않은 behavior가 발생하지 않을 것이다.
When accessing shared data across CPUs, mutual exclusion primitives should likely be used to guarantee
pthread_mutex_t mutex;
typedef struct _node {
int value;
struct _node *next;
} NODE;
int enqueue(void) {
lock(&mutex);
NODE *temp = head; // Queue의 Header를 기억
int value = head->value; // Header의 Data를 추출
head = head->next; // Header를 그 다음으로 변경
free(temp); // 기존의 Header를 Free
unlock(&mutex);
return value; // Pop!
}
Cache Affinity
어떤 작업이 CPU1에서 실행되고 다음 번에도 같은 CPU에서 실행된다면, Memory에서 필요한 정보를 Cache로 가져오는 과정이 필요하지 않기 때문에 우수한 성능을 가질 수 있게 된다.
그러므로 Signle Core에서와는 다르게, 가능한 같은 process는 같은 CPU에서 실행되도록 노력해야 한다.
A multiprocessor scheduler should consider cache affinity(캐시-친화적인) when making its scheduling decision
Solution 1: Single Queue Multiprocessor Scheduling(SQMS)
하나의 Queue를 두고 n개의 코어로 작업하는 방법
Core마다 ready process queue를 따로 만든다
만약 Queue에 A B C D E 라는 작업이 있다면
CPU1: AEDCBA
CPU2: BAEDCB
CPU3: CBAEDC
CPU4: DCBAED
이렇게 CPU1부터 시작해서 Queue로 부터 하나씩 Dequeue하고,
Time Slice가 끝나면 순차적으로 Enqueue하는 것을 반복한다.

그러나 Shared Data Structure이므로 이에 대한 locking이 필요하고 계속 동기화 작업이 반복되어야 한다.
-> Lack of scalability 확장성에 한계가 있다.
또한 job이 여러 CPU에서 수행됐다 말았다 반복하면서 Cache Affinity 문제를 가진다.
만약 SQMS에서 Cache Affinity를 제공하면 어떨까?
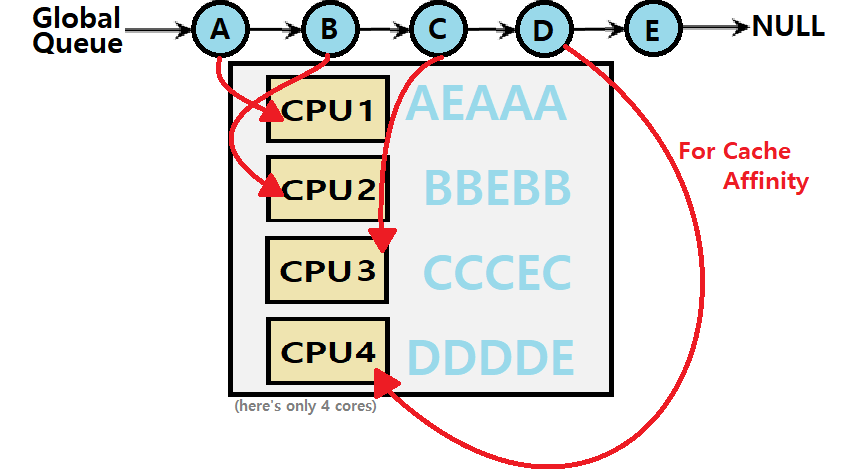
이전의 SQMS 그림보다는 affinity를 보존하므로 우수하다.
그러나 이러한 구조를 실제로 구현하는 것이 어렵다.
좀 더 개선된 Multiprocessor Scheduling Algorithm이 필요하다.
Solution 2: Multi-queue Multiprocessor Scheduling (MQMS)
multiple scheduling queues를 가져서 processor가 자신만의 ready queue를 가지도록 한다.
각 CPU는 자신만의 Private queue를 가지므로 queue를 공유하지 않아 Lock & Unlock의 Synchronizaiton이 필요하지 않다. 이를 통해 동기화 문제를 해결할 수 있고, Cache Affinity도 지켜진다.
MQMS provides more scalability and cache affinity
각 queue는 각자의 특정한 스케줄링 규율을 따르고
job이 system에 도착하면 임의의 한 queue에 들어간다.
각 queue는 round-robin하게 process를 schedule한다.

그러나 MQMS는 Load Imbalance 문제가 있다. 이는 CPU의 job load가 불균형한 것을 말한다.


이는 fair share의 rule을 깨버린 것이고, 이럴 때 동일한 양의 자원을 받을 수 있도록 프로세서를 옮겨야 한다.
(Job Migration)
이때 수행하는 주체는 내 ready queue가 비어있는 애다. 내 꺼가 비어있으면 다른 곳에서 땡겨 온다.

이렇게 job을 이리저리 옮겨 다니면 MQMS의 scalability 장점이 떨어지고 구현이 복잡하다.
그러나 load imbalance는 꼭 해결되어야 하는 문제다.
Work Stealing
migration을 할 때 무엇을/어디로 이동시킬지 결정하는 방법 중 하나이다.
move jobs between queues
- job의 개수가 적은 queue를 source queue로 정한다
- source queue는 때때로 다른 target queue를 보면서 target queue의 job 개수가 source queue의 job 개수보다 많으면 job을 1개 혹은 1개 이상 훔쳐온다.
(역전되지 않을 정도로만 work stealing)
그러나 이는 High overhead와 trouble scaling의 문제를 가진다.
너무 자주 일어나면 안 되므로 차이가 너무 크지 않다면 어느 정도의 load imbalancing은 봐준다.
-> 시간, 차이가 어느 정도 이상일 때 조심스럽게 stealing
https://satisfactoryplace.tistory.com/53
[Operating Systems] Multiprocessor Scheduling
우리 주변의 컴퓨터들을 보더라도, 대부분의 컴퓨터들은 듀얼코어 이상의 CPU를 사용하고 있다. 게다가, 요즘에는 일반 데스크탑 용도의 컴퓨터에도 6코어, 8코어 CPU를 사용하고 있으니,단순히 Si
satisfactoryplace.tistory.com
https://velog.io/@junttang/OS-1.8-Process-Virtualization-7-Multiprocessor
OS - 1.8 (PV) (7) Multicore Schedulings
지금까지는 Single CPU 환경에서의 Scheduling에 대해 알아보았다. 하지만, Modern Computer는 대부분이 Multiprocessor 환경이다. 따라서, 우리는 Multiprocessor에서의 Scheduling도 고민해봐야한다.
velog.io
https://velog.io/@spdlqj4818/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-Multiprocessor-Scheduling
운영체제 - Multiprocessor Scheduling
운영체제
velog.io
'SKKU SW > Operating System' 카테고리의 다른 글
| [OS] [Linux / UNIX] sync, fsync 함수 (1) | 2024.06.09 |
|---|---|
| [OS] Anonymous pipe와 Named pipe (0) | 2024.06.07 |
| [OS] Multiprocessor Scheduling(1) - Cache Coherence(캐시 일관성) & Bus snooping(버스 스누핑) (2) | 2024.03.26 |
| [OS] System call 시스템 콜 (0) | 2024.03.25 |
| [OS] main함수의 int argc와 char *argv[] (0) | 2024.03.13 |
Multi core -> Multiprocessor
Thread 개념을 이용해 parallel programming을 해야 한다. (Multithreading)
Cache Coherence
: Multicore 환경에서 각 CPU Core에는 개별적인 Cache가 존재하고, 이 Core들은 공통된 Bus를 통해 Memory에 접근하는데, 이때 각 Core Cache, 그리고 Main Memory 사이에서 Data들의 Consistency를 어떻게 유지할 것인가?
Bus snooping
https://gusdkstudyhard.tistory.com/139
[OS] Multiprocessor Scheduling(1) - Cache Coherence(캐시 일관성) & Bus snooping(버스 스누핑)
Single Core 환경은 (CPU - Cache) ----- Memory 형태로 되어 있다. Cache는 Main Memory보다 용량은 작지만, 주요 data들을 모아 둔 작고 빠른 임시저장장치이다. 이 Cache를 이요함으로써 CPU와 Memory 간의 다소 느
gusdkstudyhard.tistory.com
1편에 적었다.
Synchronization
core가 n개라면 최대 n개의 core가 각각 Queue에 접근하여 enqueue하거나 dequeue하는 상황이 생길 것이다.
Application program이 Shared Data를 접근할 경우에는 lock과 unlock으로 synchronization을 보장해 주어야만 의도치 않은 behavior가 발생하지 않을 것이다.
When accessing shared data across CPUs, mutual exclusion primitives should likely be used to guarantee
pthread_mutex_t mutex;
typedef struct _node {
int value;
struct _node *next;
} NODE;
int enqueue(void) {
lock(&mutex);
NODE *temp = head; // Queue의 Header를 기억
int value = head->value; // Header의 Data를 추출
head = head->next; // Header를 그 다음으로 변경
free(temp); // 기존의 Header를 Free
unlock(&mutex);
return value; // Pop!
}
Cache Affinity
어떤 작업이 CPU1에서 실행되고 다음 번에도 같은 CPU에서 실행된다면, Memory에서 필요한 정보를 Cache로 가져오는 과정이 필요하지 않기 때문에 우수한 성능을 가질 수 있게 된다.
그러므로 Signle Core에서와는 다르게, 가능한 같은 process는 같은 CPU에서 실행되도록 노력해야 한다.
A multiprocessor scheduler should consider cache affinity(캐시-친화적인) when making its scheduling decision
Solution 1: Single Queue Multiprocessor Scheduling(SQMS)
하나의 Queue를 두고 n개의 코어로 작업하는 방법
Core마다 ready process queue를 따로 만든다
만약 Queue에 A B C D E 라는 작업이 있다면
CPU1: AEDCBA
CPU2: BAEDCB
CPU3: CBAEDC
CPU4: DCBAED
이렇게 CPU1부터 시작해서 Queue로 부터 하나씩 Dequeue하고,
Time Slice가 끝나면 순차적으로 Enqueue하는 것을 반복한다.
그러나 Shared Data Structure이므로 이에 대한 locking이 필요하고 계속 동기화 작업이 반복되어야 한다.
-> Lack of scalability 확장성에 한계가 있다.
또한 job이 여러 CPU에서 수행됐다 말았다 반복하면서 Cache Affinity 문제를 가진다.
만약 SQMS에서 Cache Affinity를 제공하면 어떨까?
이전의 SQMS 그림보다는 affinity를 보존하므로 우수하다.
그러나 이러한 구조를 실제로 구현하는 것이 어렵다.
좀 더 개선된 Multiprocessor Scheduling Algorithm이 필요하다.
Solution 2: Multi-queue Multiprocessor Scheduling (MQMS)
multiple scheduling queues를 가져서 processor가 자신만의 ready queue를 가지도록 한다.
각 CPU는 자신만의 Private queue를 가지므로 queue를 공유하지 않아 Lock & Unlock의 Synchronizaiton이 필요하지 않다. 이를 통해 동기화 문제를 해결할 수 있고, Cache Affinity도 지켜진다.
MQMS provides more scalability and cache affinity
각 queue는 각자의 특정한 스케줄링 규율을 따르고
job이 system에 도착하면 임의의 한 queue에 들어간다.
각 queue는 round-robin하게 process를 schedule한다.
그러나 MQMS는 Load Imbalance 문제가 있다. 이는 CPU의 job load가 불균형한 것을 말한다.
이는 fair share의 rule을 깨버린 것이고, 이럴 때 동일한 양의 자원을 받을 수 있도록 프로세서를 옮겨야 한다.
(Job Migration)
이때 수행하는 주체는 내 ready queue가 비어있는 애다. 내 꺼가 비어있으면 다른 곳에서 땡겨 온다.
이렇게 job을 이리저리 옮겨 다니면 MQMS의 scalability 장점이 떨어지고 구현이 복잡하다.
그러나 load imbalance는 꼭 해결되어야 하는 문제다.
Work Stealing
migration을 할 때 무엇을/어디로 이동시킬지 결정하는 방법 중 하나이다.
move jobs between queues
- job의 개수가 적은 queue를 source queue로 정한다
- source queue는 때때로 다른 target queue를 보면서 target queue의 job 개수가 source queue의 job 개수보다 많으면 job을 1개 혹은 1개 이상 훔쳐온다.
(역전되지 않을 정도로만 work stealing)
그러나 이는 High overhead와 trouble scaling의 문제를 가진다.
너무 자주 일어나면 안 되므로 차이가 너무 크지 않다면 어느 정도의 load imbalancing은 봐준다.
-> 시간, 차이가 어느 정도 이상일 때 조심스럽게 stealing
https://satisfactoryplace.tistory.com/53
[Operating Systems] Multiprocessor Scheduling
우리 주변의 컴퓨터들을 보더라도, 대부분의 컴퓨터들은 듀얼코어 이상의 CPU를 사용하고 있다. 게다가, 요즘에는 일반 데스크탑 용도의 컴퓨터에도 6코어, 8코어 CPU를 사용하고 있으니,단순히 Si
satisfactoryplace.tistory.com
https://velog.io/@junttang/OS-1.8-Process-Virtualization-7-Multiprocessor
OS - 1.8 (PV) (7) Multicore Schedulings
지금까지는 Single CPU 환경에서의 Scheduling에 대해 알아보았다. 하지만, Modern Computer는 대부분이 Multiprocessor 환경이다. 따라서, 우리는 Multiprocessor에서의 Scheduling도 고민해봐야한다.
velog.io
https://velog.io/@spdlqj4818/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-Multiprocessor-Scheduling
운영체제 - Multiprocessor Scheduling
운영체제
velog.io
'SKKU SW > Operating System' 카테고리의 다른 글
| [OS] [Linux / UNIX] sync, fsync 함수 (1) | 2024.06.09 |
|---|---|
| [OS] Anonymous pipe와 Named pipe (0) | 2024.06.07 |
| [OS] Multiprocessor Scheduling(1) - Cache Coherence(캐시 일관성) & Bus snooping(버스 스누핑) (2) | 2024.03.26 |
| [OS] System call 시스템 콜 (0) | 2024.03.25 |
| [OS] main함수의 int argc와 char *argv[] (0) | 2024.03.13 |